

海华233圣约翰
“深度求索”创始人17岁考入浙大,团队成员大多来自国内顶尖院校
0
40 丨2个月前
近日,“来自东方的神秘力量”又一次震撼海外人士心脏,它就是DeepSeek。
游戏科学创始人、CEO,《黑神话:悟空》制作人冯骥评价DeepSeek:可能是个国运级别的科技成果。
冯骥表示:“希望DeepSeek R1会让你对当前最先进的AI祛魅,让AI逐渐变成你生活中的水和电。太幸运了!太开心了!这样震撼的突破,来自一个纯粹的中国公司。知识与信息平权,至此又往前迈出了坚实的一步。”
为什么DeepSeek能出圈?
在硅谷,DeepSeek很早就被称作“来自东方的神秘力量”,也是网上热议的“杭州六小龙”之一。
真正让DeepSeek火出圈的是2024年12月26日,这家公司宣布上线并同步开源的 DeepSeek-V3模型,并公布了长达53页的训练和技术细节。
它以1/11的算力、仅2000个GPU芯片训练出性能超越GPT-4o的大模型。其总训练成本只有557.6万美元,而GPT-4o的约为1亿美元,使用25000个GPU芯片,双方的成本至少是10倍的差距。
在性能上,DeepSeek-V3在数学、代码能力和中文知识问答方面还超过了ChatGPT-4o。
国外独立测评机构Artificial Analysis测试后,发出了“超越了迄今为止所有开源模型”的惊叹;Meta科学家田渊栋感慨:“这是非常伟大的工作。”
“性价比”是商业社会中的制胜法宝之一,DeepSeek也因创新的模型架构和史无前例的性价比被称为“大模型界的拼多多”,引发字节、阿里、百度等大厂的大模型价格大战。
2025年1月20日下午,中共中央政治局常委、国务院总理李强主持召开专家、企业家和教科文卫体等领域代表座谈会,听取对《政府工作报告(征求意见稿)》的意见建议。
在此次座谈会上,共有9人先后发言,其中就有深度求索(DeepSeek)创始人梁文锋。
梁文锋是谁?
低调的梁文锋是个80后,出生在广东的一个五线城市,父亲是一名小学老师。他毕业于浙江大学,主修软件工程,人工智能方向。
17岁时,梁文锋考入浙大,读的是电子工程系人工智能方向,毕业后在浙大攻读硕士研究生,论文题目是《基于低成本PTZ摄像机的目标跟踪算法研究》。
2015年,30岁的梁文锋和朋友一起创办了杭州幻方科技有限公司,立志成为世界顶级的量化对冲基金。2016年10月,幻方量化推出第一个AI模型,第一份由深度学习生成的交易仓位上线执行。到2017年底,几乎所有的量化策略都采用AI模型计算。
2023年5月,38岁的梁文锋宣布做通用人工智能(AGI)。7月,他正式创办杭州深度求索人工智能基础技术研究有限公司,就是DeepSeek公司,专注于AI大模型的研究和开发,公司设在杭州。
有同事评价梁文锋:完全不像一个老板,而更像一个极客。因为作为老板,他本人每天都在写代码、跑代码,学习能力惊人。
从公开的工作经历和职业生涯来看,梁文锋在量化投资和高性能计算领域具有深厚的背景和丰富的经验,创业范畴横跨金融和人工智能领域。
DeepSeek团队:
90后、95后为主,喜欢“高潜力年轻人”
据报道,DeepSeek的员工规模不到140人,是Open AI的十分之一左右。据领英网站检索样本发现,DeepSeek员工85%以上拥有硕士学位,40%以上有博士学位。团队成员平均年龄约为28岁,90后占比超75%,95后(1995年后出生)员工占比50%以上。该公司成员大多毕业于北大、清华、中科大等国内顶尖院校,也有少数毕业于麻省理工学院、卡内基梅隆大学等海外知名高校。同时DeepSeek的员工中也有相当一部分具有交叉学科背景。
和动辄上千人的“大厂”AI开发团队相比,DeepSeek百余人的规模显得相当精炼,并且在选人标准上两者也大有不同:互联网公司一般看重成熟的经验,最好有在核心项目成功过的经历,而DeepSeek则喜欢“高潜力年轻人”。以该公司选择的“稀疏训练”技术路径为例,刚毕业的博士生由于在学校里接触过相关前沿课题,对这一技术路径更加熟悉,而“业界老鸟”则不一定对最新技术能保持高度敏感。
据“智能涌现”,一名曾与DeepSeek有过合作的猎头表示,DeepSeek非常偏爱没有工作经验的年轻人,而且指明不要资深人士,“工作经验在3~5年已经是最多的了,工作超8年的基本就pass了”。
梁文锋曾在采访中表示,留住年轻人才的方法主要是“高薪”和“算力管够”两条路。业内人士表示,DeepSeek的薪资水平能够对标业内任何顶尖机构,而且人才如果在字节跳动等取得offer,DeepSeek还会加码竞争。DeepSeek开出的应届工程师薪酬已经等同于业界同等岗位的“总监/经理”的薪酬了。
此外梁文锋非常推崇“极客文化”,在公司内部推行扁平化管理,并且鼓励员工个人发挥潜能进行学习和创新。DeepSeek也不会采用互联网巨头常用的“赛马”机制,减少团队内耗。在算力资源的调配上,梁文锋对每个人都不设上限,只要提出有潜力的思路,他都会给员工调拨足够的资源进行尝试研究。据悉产生R1模型的技术思路就是一名年轻员工“突发奇想”提出的点子,梁文锋为他搭配了一个团队,“花了几个月时间才跑通(技术路线)”。事实证明,DeepSeek这种“轻经验、重潜力”的用人思路,为中国AI界迎来了一次划时代的创新发展。
在团队配置上,DeepSeek团队只有139名研发人员,对比ChatGPT的OpenAI团队则有1200名研究人员,团队规模是DeepSeek的近乎9倍之多。近期热门话题“雷军千万年薪挖95后天才AI少女”,这位AI少女就是DeepSeek团队的研发人员,但小米和当事人并未就此回应。
OpenAI前政策主管、Anthropic联合创始人Jack Clark曾这样评价DeepSeek:“雇用了一批高深莫测的奇才”,还认为中国制造的大模型,“将和无人机、电动汽车一样,成为不容忽视的力量。”
通过招聘网站注意到,深度求索公司的北京子公司正在招人,现共放出了52个岗位,包括深度学习研究员、核心系统研发工程师以及资深ui设计师等,均为14薪。
其中,薪资最高的为核心系统研发工程师(校招),薪资范围为6万元-9万元;除此之外,大部分岗位的起薪在2万元及以上。
注:本文引自光明社教育家,内容来源橙柿互动·都市快报、红星新闻
圣约翰
 0
0
 0
0
 广告
广告
平台操作员
6
4000
 广告
广告
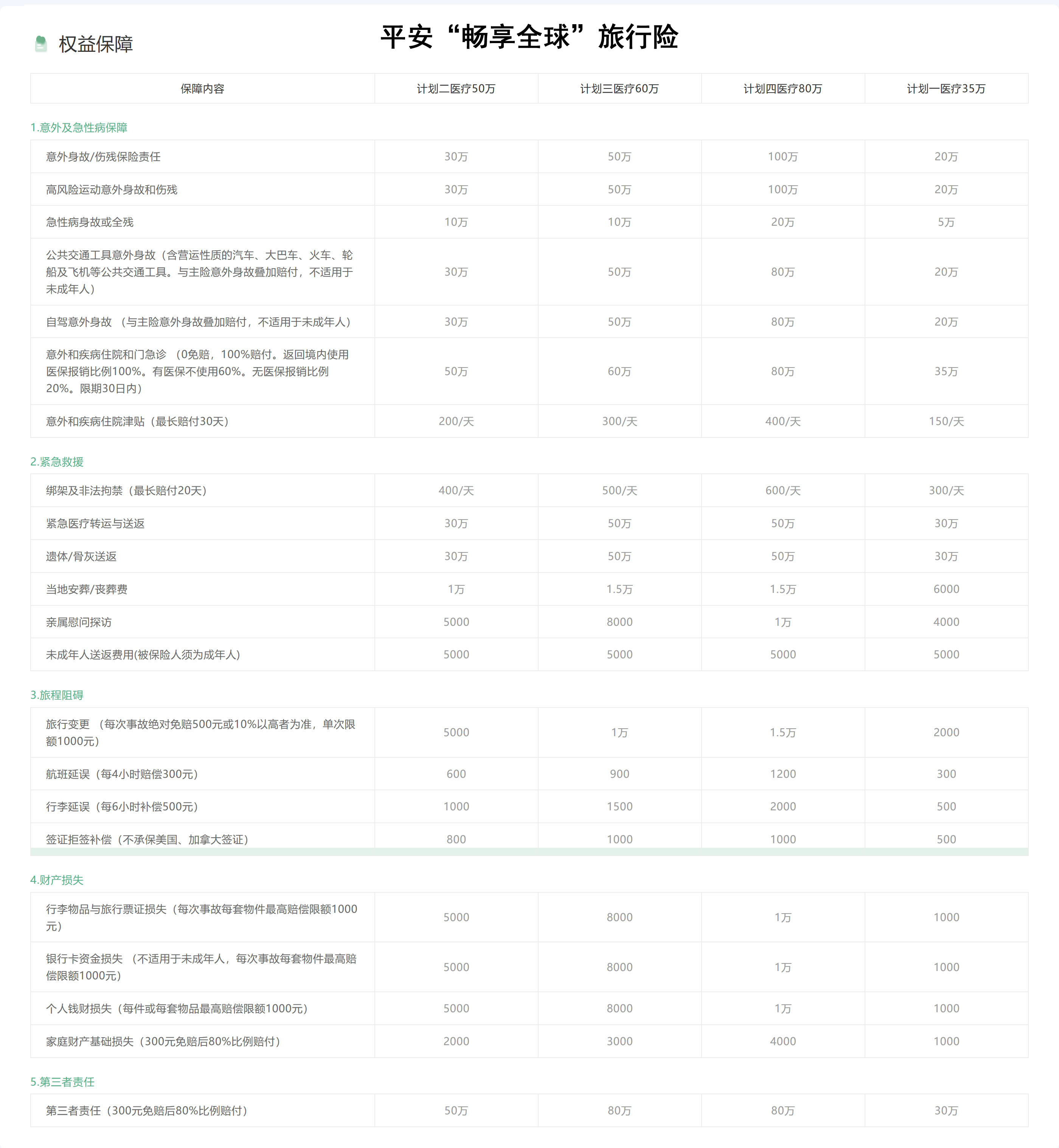
旅居🇹🇭泰国首选保险🧧(境外医疗保险)更新至2025.3.21
31
1050
 广告
广告
爱家助手,大理石加工和安装
31
 广告
广告
武吉士地铁口三室两卫公寓 超大主人房
21
1700
 广告
广告
TOP3 律师团队全方位服务刑事,移民,民商诉讼等服务
31
电话
 广告
广告
🇫🇷小巴黎2区卢浮宫附近温馨小屋长租
21
450欧
 广告
广告
煙斗
20
 广告
广告
🌟 뉴월드超市附近 门市出租 🎉
24
 广告
广告
海华233上免费发布求职招聘、房屋租售、二手转让、同城资讯等信息
31
 广告
广告
加拿大冰酒,红酒对华贸易招聘兼职销售!
6
 广告
广告
白色吊灯
14
10
 广告
广告
OCCIDENT线上保险办理
31
0
 广告
广告
本人48岁没身份 找个油锅二手三手 热菜杂工。乡下郊区都行
6
 广告
广告
大学城套间带独立卫生间 房屋状态新 Av. del Primat Reig
21
750
 广告
广告
广告招商版位| 亚利桑那州站—本地商家与个人服务限时免费招募中!!
31
0
 广告
广告
【你好搬家公司】🧧🧧让福气到你家
31
广告
求职司机
6
 广告
广告
1月5日一年一度的免费滑冰盛会!
30
 广告
广告
餐饮生意不好也是有原因的!出品好吃但谁知道啊!广告得做。
7
 广告
广告
房屋出售
29
0
广告
paris porte de Choisy 附近招聘长期全工服务员 ,要熟手。 联系电话:0778112701
6
 广告
广告
免费商家和个人服务推广
31
广告
10
 广告
广告
蔡凯傑 BentonRealtor 杰克逊维尔区域•买卖房屋
23
 广告
广告
土耳其毛肚,牛百叶!
36
10.30$
 广告
广告
餐店生意出顶
26
0
 广告
广告
Malden杂费全包单房出租!近巴士地铁、中超和中歺馆,环境优美!
21
750
 广告
广告
法国政府新年伊始展开一连串民生新措施
30
广告
出租 小巴黎8区 Studio
21
1200
 广告
广告
BM米兰卫浴,畅销百元店
30
